昨天,AI创业公司 DeepSeek 团队低调上线了新一代大型语言模型 DeepSeek-V3-0324。该模型参数规模高达6850亿(采用 Mixture-of-Experts 多专家混合架构),却在 Hugging Face 上以 MIT 许可证开源发布,允许免费商用。更令人关注的是,DeepSeek 官方通过 OpenRouter 平台提供了 免费 API 接口。这意味着开发者无需付费即可调用这一强大的模型,将其集成到自己的应用中,直接体验它的卓越能力。
作为 DeepSeek 系列的最新力作,V3-0324 被视为旗舰聊天模型的新迭代。它继承了前代模型优秀的对话和编程基因,并在多个方面取得显著提升。社区在模型发布当日即展开热议,许多AI爱好者发现这款模型性能远超前代,甚至可以媲美某些封闭源码的顶尖模型 。
本期小编将带大家深入了解一下DeepSeek-V3-0324 的技术亮点、为大家分享免费API的介入方法。

DeepSeek-V3-0324技术亮点与能力
DeepSeek-V3-0324 相较前代模型,在模型规模、推理能力、理解与生成能力等方面都有突破性进展,也支持多轮对话、具备强大的编程和多语言能力。以下是该模型的主要亮点:
1.模型规模与架构:
DeepSeek-V3-0324 拥有 6850亿参数的超大规模架构,是当前参数量最大的开源模型之一 (OpenRouter)。不同于传统Transformer一次激活所有参数,DeepSeek V3 采用了Mixture-of-Experts (MoE,多专家混合)架构,使每次推理仅激活约370亿参数子模型。这一选择性激活机制极大提高了效率,在保证性能的同时降低计算需求。模型还引入了前沿的多头潜在注意力机制 (MLA) 和多Token并行生成技术 (MTP),一次可并行输出多个token,从而使生成速度提升近 80% 。在 Apple M3 Ultra 芯片的 Mac Studio 上,经过4比特量化的模型本地推理速度据报告可超过每秒20 token ——这在以往需要庞大GPU集群的大模型领域是革命性的效率提升。
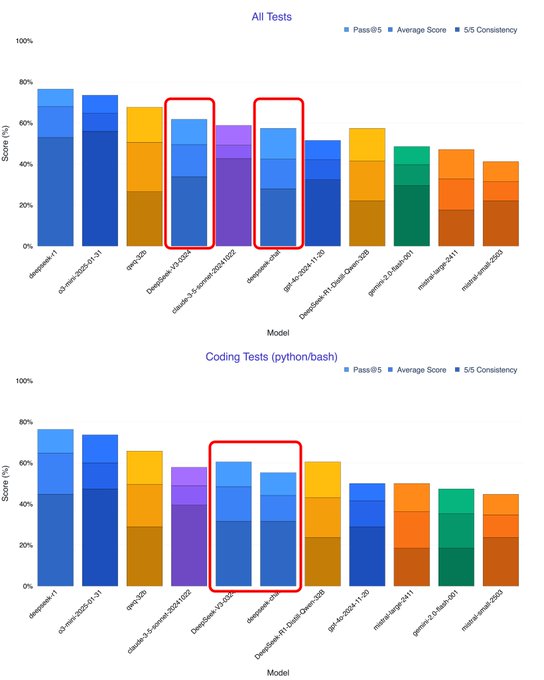
2.推理与逻辑能力:
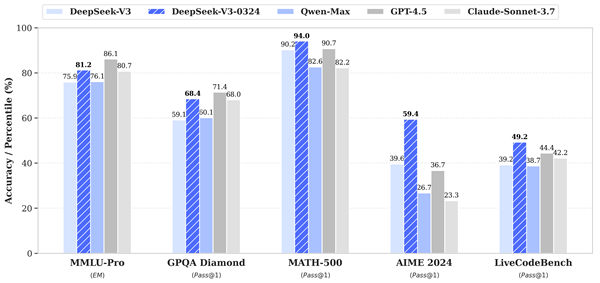
新模型在复杂推理任务上有明显增强。在综合知识问答基准 MMLU 上,官方指标显示 V3-0324 的5-shot准确率达到 81.2%(前代为75.9%),大幅超越前代模型;有社区测试甚至报告其成绩可达 87.1%,超过了同参数量级的 LLaMA3.1-405B 模型。对于数学和逻辑推理挑战,DeepSeek-V3-0324 同样表现突出:例如在高难度数学竞赛题集 AIME 上准确率提升近20个百分点 。
这些数据表明该模型的推理能力已经跻身开源模型的领先梯队。
3.理解与生成能力:
得益于大规模高质量训练语料和优化的指令微调,V3-0324 对文本的理解更加深入,对用户意图的把握更加精准。在生成方面,模型输出的内容连贯性和上下文一致性都有提升。相较前代模型偏向轻松对话的风格,V3-0324 更倾向于严谨、专业的回答风格。
官方指出新版本对中长篇内容的创作质量有提高,文字风格与DeepSeek的强化学习模型 R1 对齐,更加严谨丰富。在多轮交互中,模型能够更好地记忆和利用之前的对话内容,支持上下文长度高达 131072 个 token——这意味着一次对话或任务可以包含数百页的文本,模型仍能保持理解和连贯回应。这种超长上下文能力为复杂对话和长文档分析提供了可能。
4.多轮对话与上下文管理:
DeepSeek-V3-0324 专为对话场景优化,支持多轮对话。它对系统提示和用户多次交互的处理比以往更为出色。根据官方模型卡说明,新版本改进了多轮交互下的内容重写能力,能在连续对话中保持语义一致并按需调整回答。无论是持续的问答跟进,还是对用户上一轮提示的上下文引用,模型都能较好地承接对话。例如在中文写作场景下,V3-0324 可以根据用户反馈对上一版草稿进行重写润色,整个过程流畅自然。
5.编程能力:
编程代码生成与理解是 DeepSeek 系列的一大强项。V3-0324 进一步提升了代码编写和调试能力。在知名的编程基准 HumanEval 中,该模型的 Pass@1 正确率达到 65.2% ——相比多数开源模型有显著优势,甚至接近某些专有模型的水平(例如 OpenAI 的 GPT-4 系列的精简版)。
社区开发者测试发现,DeepSeek-V3-0324 可以一口气生成数百行的代码而不出错,代码逻辑清晰且可成功运行。这在构建网页前端、游戏脚本等应用中大有裨益。官方指出新版本生成的前端代码不仅可执行性更高,而且界面样式也更加美观。
此外,V3-0324 对函数调用格式的支持也更完善,函数调用参数填充的准确率相较旧版显著提升 。
6.多语言能力:
作为一家中国团队出品的模型,DeepSeek-V3-0324 在中英文双语能力上表现均衡出色,并对中文做了特别优化。官方模型卡披露,新版本显著提升了中文写作水平 :输出文本的文风和内容质量更高,更接近人类写作风格;在中文长文、书信写作以及翻译任务上都有优化。
同时,从社区反馈看,DeepSeek-V3-0324 对英语等其他主要语言的理解与生成也毫不逊色。一项多语言综合测试表明该模型在多语种处理上优于前代,接近业界领先水平 。这使其成为真正多语言的通用模型,能够满足不同语言环境下的对话和内容创作需求。
7.评测表现:
在各类权威基准评测中,DeepSeek-V3-0324 成绩斐然,多项指标位居前列。除了前面提到的 MMLU 和 HumanEval,高难度专业问答 GPQA 准确率提升至 68.4(高出前代9个百分点);代码竞赛题集 LiveCodeBench 得分提高了 10.0;
在其他如数学、常识问答等评测上也都有全面超越前代的表现。有测评者评价:“新的 DeepSeek V3 在各项测试上均有巨大飞跃,已经成为最强的开源非推理模型,成功超越Anthropic公司的 Sonnet 3.5系列”。尽管在复杂推理链条任务上可能仍略逊于DeepSeek自家的R1推理模型,但就通用对话和知识问答能力而言,V3-0324 已经站上了开源领域的顶峰。
综上所述,DeepSeek-V3-0324 在模型规模和架构创新上树立了里程碑,并通过强化训练显著提升了多方面能力——从逻辑推理、代码编写到语言理解、内容创作,无不表现出行业领先的水准。这为开发者提供了一个功能强大的通用AI引擎,并且通过开放API可以方便地加以利用。
DeepSeek-V3-0324API的接入方式与调用教程
OpenRouter DeepSeek-V3-0324免费API接口地址:https://openrouter.ai/deepseek/deepseek-chat-v3-0324:free(点击直达)
DeepSeek-V3-0324 的免费 API 接口由 OpenRouter 平台提供。OpenRouter 是一个聚合了数百种AI模型的统一接口平台,兼容 OpenAI API 的请求格式 。开发者只需简单几步,就能通过 OpenRouter 免费调用 DeepSeek-V3-0324:
1. 注册 OpenRouter 并获取 API Key: 打开 OpenRouter 官网(openrouter.ai)注册账号,并进入账户设置页面生成一个 API Key(点选“Create API Key”即可获取密钥字符串)。这个 API Key 在调用接口时用于身份认证。
2. 构造 API 请求: OpenRouter 提供与 OpenAI API 相同风格的 REST 接口。调用 DeepSeek-V3-0324 时,使用 Chat Completions API 接口即可。具体来说,发送一个 POST 请求到:
https://openrouter.ai/api/v1/chat/completions
请求头需包含:
Content-Type: application/jsonAuthorization: Bearer YOUR_API_KEY(将YOUR_API_KEY替换为上一步获取的实际密钥)
请求内容为 JSON,必须包含模型名称和对话消息。例如:
{
"model": "deepseek/deepseek-chat-v3-0324:free",
"messages": [
{"role": "user", "content": "你好!请用一句话介绍DeepSeek-V3-0324模型。"}
],
"temperature": 0.7,
"top_p": 1.0
}
上述 JSON 中,model 字段指定了调用 DeepSeek-V3-0324 的免费版本(注意模型名称后包含:free后缀),消息列表 messages 中可以传入多轮对话内容(此处仅包含用户的提问),temperature、top_p 等参数可选地控制生成随机性和多样性。temperature 越低,回答越严谨确定;越高则可能更丰富多变。
3. 解析响应: 成功请求后,OpenRouter 将返回一个 JSON 响应,其中包含模型生成的回复。其结构与OpenAI的ChatGPT接口类似,例如:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1698230937,
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "DeepSeek-V3-0324 是一款拥有6850亿参数的开源中文-英文双语大语言模型,在各项任务上具有出色的理解和生成能力。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 36,
"total_tokens": 56
}
}
其中 choices[0].message.content 即为模型的回答文本。开发者可以在自己应用中提取并展示该内容。
4. 调用示例: 开发者可以使用任意支持HTTP请求的编程语言来调用 API。以下给出一个使用 Python requests 库的简单示例:
import requests
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer sk-XXXXXXXXXXXXXXXXXXXXX" # 您的API Key
}
data = {
"model": "deepseek/deepseek-chat-v3-0324:free",
"messages": [
{"role": "user", "content": "用一句话描述DeepSeek-V3-0324的亮点。"}
]
}
response = requests.post(url, headers=headers, json=data)
answer = response.json()["choices"][0]["message"]["content"]
print(answer)
以上代码会打印出 DeepSeek-V3-0324 对用户请求的回答内容。例如,它可能输出:"DeepSeek-V3-0324 拥有6850亿参数和多专家架构,在开源模型中性能出众,并提供免费API供公众使用。".
5. 使用限制: 当前 DeepSeek-V3-0324 免费API 对每次调用的上下文长度支持非常大(最多131072 tokens),足以传输长篇内容。不过出于资源考虑,OpenRouter 对免费接口可能实施总体的流量控制。虽然每个请求无需付费,但高并发或超大规模的调用可能会触发一定的频率限制。如果遇到 rate limit 提示,可以稍作等待或减少请求频率。对于普通开发者的测试和中小规模应用而言,一般无需担心额度问题。OpenRouter 团队也鼓励合理使用免费模型接口,并在 Discord 社区提供支持 。
需要强调的是,通过 OpenRouter 平台调用意味着您无需自行部署庞大的模型,也不必担心底层基础设施兼容。OpenRouter 会对不同提供商的请求和响应进行标准化处理,开发者可以像调用OpenAI官方接口一样便捷地使用 DeepSeek 等第三方模型。总之,几分钟的配置,即可让您零成本接入这个强大的模型,在自己的产品或项目中尽情发挥其能力。
应用场景
作为一款功能全面的大语言模型,DeepSeek-V3-0324 在众多场景下都有用武之地:
- 创作写作助手:借助其出色的语言生成能力和超长上下文,DeepSeek-V3-0324 可用于撰写文章、博客内容、产品文案等。它能根据提示生成结构清晰、语句通顺的长篇文本,并可多轮修改润色,提高写作效率。
- 代码生成与调试:凭借接近专业水平的编程能力,V3-0324 可担任程序员的助手。例如根据自然语言描述生成代码片段、算法实现,甚至整段的程序代码。其在 Python、前端网页等领域的代码生成尤为见长。同时它还能分析给定的代码,帮助查找错误或进行优化建议。
- 知识问答与解疑:利用模型庞大的训练语料和强大的知识整合能力,可以构建智能问答系统或聊天机器人。无论是通用领域的百科问答,还是专业垂直领域(如医学、法律、金融)的咨询,DeepSeek-V3-0324 都能基于提示提供详尽的回答。配合其长上下文记忆,可以让用户就某一主题深入追问,模型逐步给出细化解答。
- 多语言翻译与教学:模型的双语能力使其胜任中英互译,以及其他语言的理解生成任务。可以将其用于实时翻译、语言学习助手、跨语言客服等场景。比如输入一段中文文章,让模型总结并翻译成英文摘要,或者请模型用西班牙语回答问题等。
- 长文档分析与报告生成:得益于超长的131k上下文窗口,DeepSeek-V3-0324 能够吃下整份报告、论文或小说等长文档,并进行摘要、分析或基于内容的问答。这对于处理企业报告、技术文档摘要、法律合同分析等非常实用。用户只需将长文档内容分段提交给模型,即可让其提炼重点或回答与内容相关的问题。
- 垂直领域定制助手:由于DeepSeek-V3-0324是开源模型,企业和开发者还可以在其基础上进行微调,训练出适应特定领域的定制模型。例如医疗诊断助手、法律顾问机器人、教育答疑助教等。在进行一些额外领域数据的fine-tune后,这些定制版仍可通过OpenRouter接口提供服务,充分利用V3-0324强大的基础能力。
总的来说,DeepSeek-V3-0324 可以视作一个通用的AI引擎,在写作创作、代码编程、问答对话、语言服务等各类应用中发挥作用。特别地,它的免费开放降低了AI应用的门槛,小到个人开发者、大到企业团队,都能轻松将其集成到具体业务中,打造各种创新功能。
对比与展望
作为当前开源社区的尖端模型之一,DeepSeek-V3-0324 常被拿来与 OpenAI、Anthropic、Google 等公司的主流模型进行对比。以下是对 DeepSeek-V3-0324 与几款主流模型的简单分析:
- 对比 GPT-4(OpenAI):GPT-4 是业界公认的顶尖闭源模型之一,以卓越的理解力和创造力著称。不过由于商业策略,GPT-4 使用需要付费,并且其具体架构和训练细节不对外公开。相比之下,DeepSeek-V3-0324 通过开源和免费API让大众触手可及。在性能上,V3-0324 在知识问答、代码生成等客观指标上已经接近 GPT-4 的水准 。
例如前文提到的 MMLU 准确率,DeepSeek 已与GPT-4相当。尽管在对话的自然性和多任务鲁棒性上,GPT-4 可能仍略胜一筹(尤其是经过强化学习人类反馈RLHF的微调,使其对人类意图拿捏更成熟),但二者差距正在迅速缩小。更重要的是,DeepSeek 的开放模式为社区创新带来了无限可能——开发者可以在其上二次训练、部署私有服务,这是闭源的 GPT-4 无法做到的。 - 对比 Claude 3(Anthropic):Anthropic 的 Claude 系列(如Claude 2,以及推测中的Claude 3)以安全性和超长上下文见长。Claude 2 已经支持10万-token级别的上下文,在对话时能容纳极长的内容。DeepSeek-V3-0324 在上下文长度上并不逊色,官方标称达到131k tokens,比Claude更进一步,能够处理更长的文本 。在对话风格上,Claude 倾向于温和、友好的语气,而 DeepSeek-V3-0324 则更偏技术理性,这可能源于两者调优侧重点的不同。就推理能力而言,据社区评测 DeepSeek-V3-0324 已超越Anthropic上一代的Claude Sonnet 3.5模型;若与Claude 3相比,DeepSeek在知识和代码方面依然具备竞争力,甚至有评价称其“几乎追平Anthropic最新的Sonnet 3.5在编程上的表现”。不过Anthropic在对话安全性、减少有害输出等方面有独特算法,而DeepSeek作为开源模型则给予开发者更多自由度去平衡安全和性能。
总体而言,DeepSeek-V3-0324 正成为封闭大模型的有力挑战者。 - 对比 Google Gemini:Google 即将推出的 Gemini(据传在2024年底发布)被寄予厚望,号称融合了AlphaGo的强化学习理念,可能在多模态方面有所突破。Gemini如果如期问世,将成为Google在AI领域对OpenAI的回应。和 Gemini 相比,DeepSeek-V3-0324 的优势在于先发和开放。在2025年初当下,DeepSeek-V3-0324已凭借实打实的性能赢得了开发者关注,而且通过MIT许可开放了使用权。即便 Google Gemini 最终在某些指标上超越DeepSeek,考虑到 Gemini 大概率是闭源商用模式,DeepSeek 的开源生态仍有其独特价值。一个有意思的类比是:Android 开源生态在移动领域的成功证明了开放策略的威力,同样地,DeepSeek 代表的开源AI路线有望通过社区协作和快速迭代,在长期与科技巨头的封闭模型分庭抗礼。
展望未来,DeepSeek-V3-0324 的发布标志着开源AI模型正迅速逼近甚至达到商业最先进模型的水平。中国的AI社区在开源方面的投入,正缩小与西方闭源模型之间的差距 。可以预见,随着更多像 DeepSeek 这样强大的模型开放出来,开发者将拥有前所未有的工具去构建创新应用。免费API的提供进一步降低了使用门槛,让AI能力真正成为普惠技术。DeepSeek 官方后续可能会发布升级版(比如 V3 后续 checkpoint 或 R 系列新模型),以及体积更小的蒸馏模型以便于部署各种设备。对于开发者来说,现在正是利用这一免费强大模型的好时机,在实际项目中发掘其价值。同时,我们也将持续关注 DeepSeek 团队和开源社区的最新动向——在开放与创新的合力下,下一代的 AI 模型很可能会再次令人惊喜,让我们拭目以待。




